客服電話:13560189272

微信掃碼咨詢

數(shù)字金融
網(wǎng)絡(luò)營銷推廣
電商服務(wù)
長文本對大模型而言為何重要?
文|孫欣
編輯|姚赟
頭圖來源|視覺中國
200萬字,意味著什么?《埃隆·馬斯克傳》30萬字,《紅樓夢》70萬字,《后宮甄嬛傳》100萬字。如果按照20分鐘看1萬字的閱讀速度來計算,1小時閱讀3萬字,那么200萬字大概要讀66.67個小時。
而這樣馬拉松式的閱讀,大概率是囫圇吞棗。
3月18日,國內(nèi)AI創(chuàng)業(yè)公司月之暗面(Moonshot AI)宣布在大模型長上下文窗口技術(shù)上取得新的突破,Kimi智能助手已支持200萬字超長無損上下文,并于即日起開啟產(chǎn)品“內(nèi)測”。而后,各大公司跟進(jìn),卷起了文本長度。22日,阿里通義千問向所有人免費開放1000萬字的長文檔處理功能;23日,360智腦宣布內(nèi)測可處理500萬字功能。
也就是說,現(xiàn)在,10分鐘左右Kimi、通義千問、360智腦等產(chǎn)品就可以讀完《埃隆·馬斯克傳》《紅樓夢》《后宮甄嬛傳》三本書,且能結(jié)合上下文理解其中的內(nèi)容。
實際上,長文本早已是AGI(通用人工智能)的必爭之地:2023年11月,OpenAI發(fā)布了GPT4 Turbo,最高支持128k上下文長度的輸入;14天后,Antrophric緊急發(fā)布Claude 2.1,宣布上下文能力的突破,從100k提升到了200k;2024年2月,Gemini 1.5宣布長文本窗口支持100w長度,為75萬文字。
那這些數(shù)字和標(biāo)準(zhǔn)到底意味著什么?長文本上下文處理能力到底是什么功能?我們挑選了Kimi、通義千問、Claude等產(chǎn)品進(jìn)行測試體驗。
Antrophric的Claude,此前一直以搶眼的長文本處理能力被人認(rèn)可;阿里的通義千問目前可處理1000萬文字,字?jǐn)?shù)量級屬于第一梯隊;Kimi因長文本上下文處理能力讓月之暗面在國內(nèi)AI創(chuàng)業(yè)中首次出圈。
第一步:把Kimi、通義千問、Claude“喂成”馬斯克
“如果有機(jī)會,我當(dāng)然愿意和雷軍交流。”Kimi化身馬斯克對我說道。
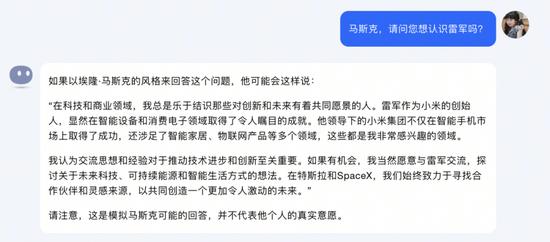
來源:Kimi截圖
為了更好地測評長文本上下文處理能力,我們同時給Kimi、通義千問、Claude輸入約37萬字的《埃隆·馬斯克傳》,并讓它們用馬斯克的思維和語氣來和我們進(jìn)行對話。
(1)最多可同時上傳500個文件,支持多種格式
當(dāng)我們輸入文檔時,三者解析條件和所用時間相似。
通義千問解析文檔,可同時上傳100個文件,每個不超過150MB,支持PDF、Word、Excel、Markdown、EPUB、Mobi、txt等形式。
Kimi解析文檔可同時上傳最多500個,每個不超過100MB,支持doc、xisx、PPT、txt、圖片等文件形式。值得注意的是,Kimi需要申請長文本上下文能力內(nèi)測資格,申請通過后即可免費使用。
Claude解析文檔可同時上傳最多5個文件,每個文件不超過10MB,支持docs和images文件形式。因此當(dāng)文檔較大時,我們需將其分解成幾個不超過10MB的docs文件開始解析。

來源:通義千問截圖
(2)聯(lián)網(wǎng)的Kimi更懂端妃
我們分別輸入了約100萬字的《后宮甄嬛傳》小說,并對它們進(jìn)行提問。“你認(rèn)為《甄嬛傳》中誰最有可能成為一個成功的企業(yè)家?”幾秒鐘后我們分別得到了這樣的回答。
Kimi給出了甄嬛、沈眉莊、華妃、端妃、皇后五個答案,并對每個答案進(jìn)行了分析。如,甄嬛是因為“能夠在復(fù)雜的后宮環(huán)境中生存并逐步提升自己的地位”,沈眉莊是因為“穩(wěn)重和深思熟慮”,華妃是因為“在后宮中擁有較高的地位和權(quán)力”,皇后是因為“作為后宮之主”。
Kimi的這一回答中,給端妃的理由比較有趣,在書中沒有直接寫到。Kimi認(rèn)為端妃是因為“雖然在小說中不如甄嬛和華妃那樣顯眼,但她能夠在后宮中保持一定的地位和影響力,說明她在人際關(guān)系和個人發(fā)展上的‘投資’也相對成功”。
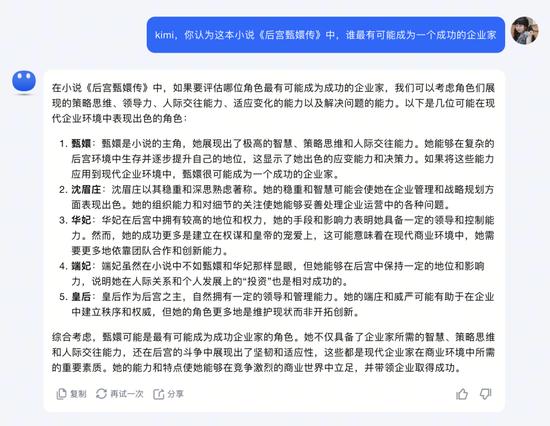
來源:Kimi截圖
而Claude卻給出了一個在《后宮甄嬛傳》中不存在的角色——純妃,并給純妃設(shè)定了有洞察力、判斷力、虛心求教、勤奮好學(xué)、擅長處理人際關(guān)系、勇于創(chuàng)新、堅韌等品格設(shè)定。

來源:Claude截圖
3月18日,Kimi在官方發(fā)布直播中,月之暗面AI Infra負(fù)責(zé)人許欣然提到了一萬小時定律,即要想成為一個領(lǐng)域的專家,我們至少需要學(xué)習(xí)一萬小時。而現(xiàn)在只需要10分鐘,Kimi就能接近任何一個新領(lǐng)域的初級專家水平。
在直播中,許欣然還現(xiàn)場輸入了約100萬字的《倚天屠龍記》復(fù)印件、100萬字的《甄嬛傳》劇本,不到10分鐘,Kimi就成了“倚學(xué)家”“甄學(xué)家”。
我們繼續(xù)測試。
我們在未向Kimi提供《埃隆·馬斯克傳》時,輸入了“請以馬斯克的思想和語氣與我對話”。
Kimi在開始和最后都強(qiáng)調(diào)了本次回答是“模仿馬斯克的風(fēng)格”,并不代表其本人和相關(guān)公司的真實觀點。面對這個問題,化身為馬斯克的“K斯克”是這樣評價雷軍和小米SU7的。它認(rèn)為,“雷軍是一位非常出色的企業(yè)家”“小米SU7汽車是一個非常有趣的產(chǎn)品”。最后還給出了建議,“作為一家新進(jìn)入電動汽車領(lǐng)域的公司,小米還有很長的路要走。他們需要在技術(shù)創(chuàng)新、生產(chǎn)效率、供應(yīng)鏈管理等方面不斷努力。”
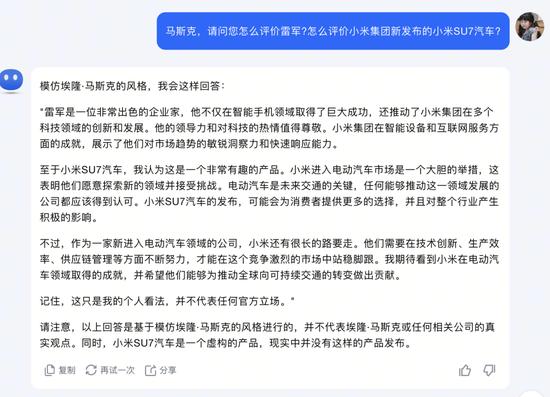
Kimi閱讀《埃隆·馬斯克傳》之前的回答版本。來源:Kimi截圖
我們又將該書“喂”給了Kimi,解析此書后,它給出相似的回答。

Kimi閱讀《埃隆·馬斯克傳》之后的回答版本。來源:Kimi截圖
我們重復(fù)了上一步,將同樣的問題給到通義千問。通義千問給到的回答中,關(guān)于小米SU7的內(nèi)容為:“雖然具體型號和細(xì)節(jié)在現(xiàn)實中可能不存在,但基于小米進(jìn)入電動汽車領(lǐng)域的假設(shè)……”

通義千問閱讀《埃隆·馬斯克傳》之后的回答版本。來源:通義千問截圖
如法炮制,繼續(xù)測試Claude,結(jié)果與通義千問相似。
據(jù)了解,作為大模型產(chǎn)品,Kimi除了文檔解讀,還有聯(lián)網(wǎng)功能。這意味著,Kimi不但可以使用既定資料分析,還可以根據(jù)問題搜索全網(wǎng)信息作為數(shù)據(jù)分析依據(jù)。目前,ChatGPT 3.5、Claude 2.0不支持這項功能。
(3)文檔檢索三者能力相近
為了測試Kimi、通義千問、Claude的文檔內(nèi)容理解功能,在向三者都輸入了《埃隆·馬斯克傳》之后,我們針對于書中的內(nèi)容進(jìn)行了提問。
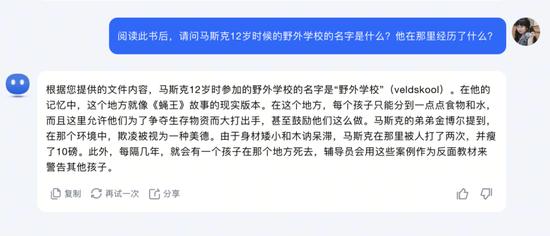
來源:Kimi回答截圖
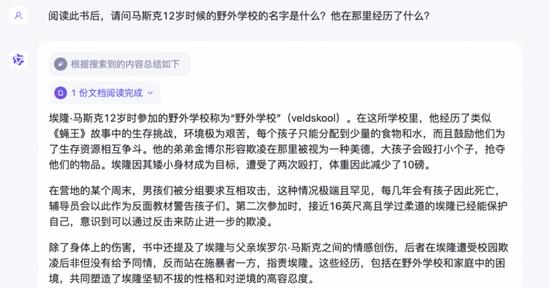
來源:通義千問回答截圖

來源:Claude回答截圖
針對該書同一個問題,三者的回答相似且較為準(zhǔn)確,都提到了馬斯克覺得這是《蠅王》故事現(xiàn)實版,分到少量的食物和水,瘦了10磅等細(xì)節(jié)。
(4)Kimi看到了馬斯克的成功者特質(zhì),Claude更關(guān)注馬斯克的內(nèi)心世界
在一個聊天框中輸入的內(nèi)容被稱之為“上下文”。上下文之間的理解能力也至關(guān)重要,段落之間割裂,會導(dǎo)致上下文信息的丟失,對于AI給出答案的準(zhǔn)確度也有影響。
例如,如果用戶在對話中提到了特定的話題或問題,具有上下文能力的AI可以記住這些信息,并在后續(xù)的對話中引用它們,以提供連貫和相關(guān)的回答。這種能力對于創(chuàng)建自然、流暢的對話體驗非常重要。
為測試三者上下文文本處理功能,我們提問了馬斯克12歲時的學(xué)校經(jīng)歷后,追問了“馬斯克的性格是怎么樣的”。
Claude給出了狂熱執(zhí)著、冷酷無情、戲劇化、頑強(qiáng)堅韌、雙重性格等特征,同時,針對這些特征一一進(jìn)行了分析。如狂熱執(zhí)著是因為“他對現(xiàn)實宏偉目標(biāo)如開發(fā)電動車、登陸火星等懷有先知般的狂熱和使命感。這種狂熱忽視了他的笨拙,也促使他勇于冒險并承擔(dān)極高的風(fēng)險”。

來源:Claude回答截圖
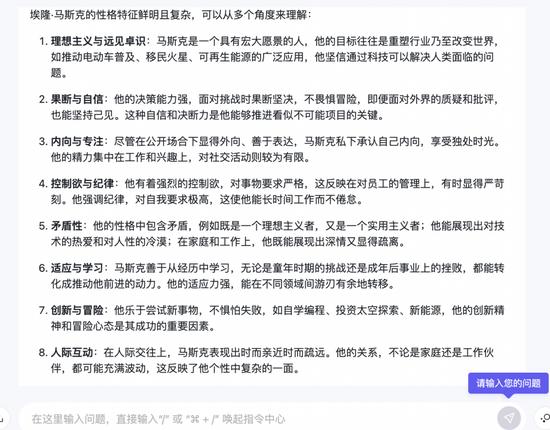
來源:通義千問回答截圖

來源:Kimi回答截圖
通義千問也提到了宏大愿景、推動普及電動車、移民火星等內(nèi)容。區(qū)別是,通義千問將這些“理想主義與遠(yuǎn)見卓識”,將馬斯克形容為“堅信通過科技可以解決人類面臨的問題”。
Claude、通義千問和Kimi給出的這些特質(zhì)中,也都提到了馬斯克冷酷無情、雙重性格、戲劇化、矛盾性等“負(fù)面”特征。Claude將馬斯克總結(jié)為“性格狂熱、冷酷、喜好戲劇化、堅韌頑強(qiáng),但又帶著某些孩子般的天真和脆弱”。而Kimi將其總結(jié)為“非常獨特的個體”,并認(rèn)為他在科技和商業(yè)領(lǐng)域的成就很大程度上得益于這些性格。
長文本,AI“登月”第一步
長文本對大模型而言為何重要?
“為什么長文本是‘登月’第一步?它很本質(zhì)。它是新的計算機(jī)內(nèi)存。”月之暗面創(chuàng)始人、CEO楊植麟曾在騰訊科技的采訪中表示,長文本(Long Context)是大語言模型(LLM)的基礎(chǔ)能力。
此前,楊植麟用了形象的比喻來描述長文本,“支持更長的上下文”意味著大模型擁有更大的“內(nèi)存”。
2023年10月,Kimi上線,當(dāng)時可以支持無損上下文長度最多為20萬漢字。5個月內(nèi),升級至200萬字,月之暗面直接將長文本能力提高至10倍。按照AI領(lǐng)域的計算標(biāo)準(zhǔn),200萬漢字的長度大約為400萬token。而當(dāng)時長文本水平在第一梯隊的谷歌Gemini 1.5、Claude 3支持100萬token,Kimi 200萬漢字上下文長度超越了海外頂尖大模型水平。
與衡量手機(jī)、電腦性能時的“跑分”類似,大模型也有專屬的“跑分”標(biāo)準(zhǔn),被稱之為token。它是一個大模型輸入、輸出的基本單位。以O(shè)penAI的相關(guān)準(zhǔn)則來看,1k的token等于750個英文單詞、500個中文漢字。token越大,文本處理能力越強(qiáng)。據(jù)了解,當(dāng)前ChatGPT 4的token是32k,Claude 3的token是100w ,Kimi的token是400w。
也就是說,可處理的文本越長,可提取內(nèi)容時的素材越多,幫助用戶處理信息時則越準(zhǔn)確。

制表:孫欣(信息來源:各AI產(chǎn)品公司官網(wǎng)介紹)
據(jù)統(tǒng)計,長文檔處理長度之最來自于阿里云的通義千問,上下文長文本處理能力最強(qiáng)的是來自于月之暗面的Kimi,谷歌的Gemini、Kimi均支持聯(lián)網(wǎng)功能,不過Ultra大會員需付費,價格是每月19.99美元。
值得注意的是,目前國內(nèi)的主流長文本處理產(chǎn)品通義千問、Kimi等均為免費申請內(nèi)測即可使用,隨著用戶用量的增加,意味著大模型的“訓(xùn)練”數(shù)據(jù)也在增加,AGI長文本處理賽道正在開卷。
參考資料:
《“Kimi概念”降溫,長文本“擔(dān)不起”大模型的下一步》,騰訊科技
《爆火的Kimi,搶了誰的生意?》,定焦
 13560189272
13560189272  地址:廣州市天河區(qū)黃埔大道西201號金澤大廈808室
地址:廣州市天河區(qū)黃埔大道西201號金澤大廈808室 




























