客服電話:13560189272

微信掃碼咨詢

數(shù)字金融
網(wǎng)絡(luò)營銷推廣
電商服務(wù)
英特爾就第一時(shí)間優(yōu)化并驗(yàn)證了80億和700億參數(shù)的Llama 3模型,憑借英特爾銳炫顯卡的強(qiáng)大性能,開發(fā)者能夠輕松在本地運(yùn)行Llama 3模型,為生成式AI工作負(fù)載提供加速。
Meta此前已經(jīng)發(fā)布了新一代Llama 3大語言模型,在發(fā)布后不久,英特爾就第一時(shí)間優(yōu)化并驗(yàn)證了80億和700億參數(shù)的Llama 3模型在英特爾AI產(chǎn)品組合上的運(yùn)行情況。在客戶端領(lǐng)域,測(cè)試表明憑借英特爾銳炫顯卡的強(qiáng)大性能,開發(fā)者能夠輕松在本地運(yùn)行Llama 3模型,為生成式AI工作負(fù)載提供加速。
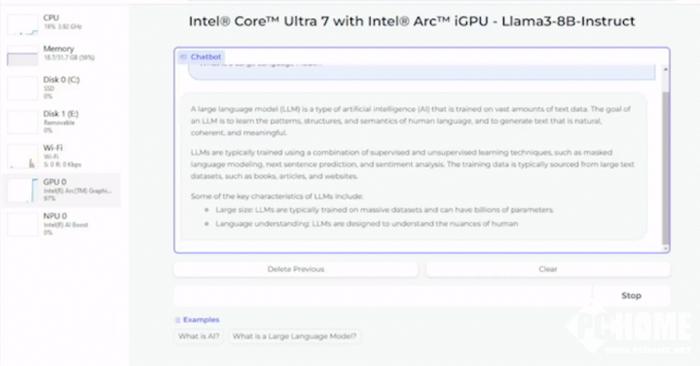
此外,英特爾酷睿Ultra H系列處理器展現(xiàn)出了高于普通人閱讀速度的輸出生成性能,而這一結(jié)果主要得益于其內(nèi)置的英特爾銳炫GPU,該GPU具有8個(gè)Xe核心,以及DP4a AI加速器和高達(dá)120 GB/s的系統(tǒng)內(nèi)存帶寬。
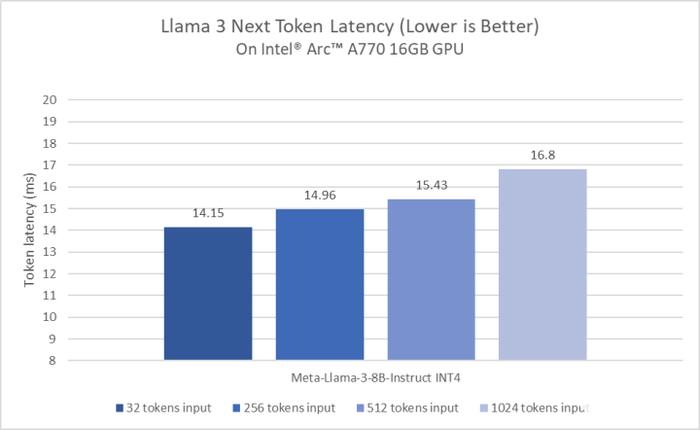
英特爾酷睿Ultra處理器和英特爾銳炫顯卡在Llama 3模型發(fā)布的第一時(shí)間便提供了良好適配,這彰顯了英特爾和Meta攜手為本地AI開發(fā)和數(shù)百萬設(shè)備的部署所作出的努力。英特爾客戶端硬件性能的大幅提升得益于用于本地研發(fā)的PyTorch和英特爾PyTorch擴(kuò)展包等豐富的軟件框架與工具,以及用于模型部署和推理的OpenVINO工具包。

而根據(jù)具體的測(cè)試樣例來看,在使用IPEX-LLM庫運(yùn)行70億參數(shù)的Mistral模型時(shí),銳炫A770 16GB顯卡每秒可以處理70個(gè)token(TPS),比使用CUDA的GeForce RTX 4060 8GB的TPS高出70%。英特爾內(nèi)部測(cè)試表明,銳炫A770 16GB顯卡在運(yùn)行大模型時(shí)能夠提供卓越的性能。相比RTX 4060,銳炫A770 16GB顯卡在運(yùn)行大多數(shù)模型時(shí)具備極有競(jìng)爭(zhēng)力或領(lǐng)先的性能,這也使其成為在本地運(yùn)行大語言模型的更優(yōu)選擇。
 13560189272
13560189272  地址:廣州市天河區(qū)黃埔大道西201號(hào)金澤大廈808室
地址:廣州市天河區(qū)黃埔大道西201號(hào)金澤大廈808室 




























